IFB文とは条件を分岐させるための構文で動作は基本的にIF文と同じですが、IFBは複数の条件で分岐でき、処理も複数書くことができます。
ELSEIFは必要だけ記述することができ、ELSEIF・ELSEは必要がなければ省略することもできます。
- 構文
- IF 式 [THEN]
真[ELSEIF 式 [THEN]]…[ELSE]偽ENDIF
- 引数
- 戻り値
IFB文とは
IFB文はIF文と同様、条件や値によって分岐する処理を書くことができます。IF文はTHEN節・ELSE節に1文しか処理が書けなかったり単独の条件式での分岐しかできませんが、IFB文は複数の条件分岐を書くことができます。
フローチャート
IFB文をフローチャートで表すと以下のいずれかになります。
条件式がTrueのときに処理を実行し、Falseのときに何も実行しないときは以下のようになります。
処理が1つの場合は、IF文で書き換えることができます。
IFB 条件式 THEN
処理
ENDIF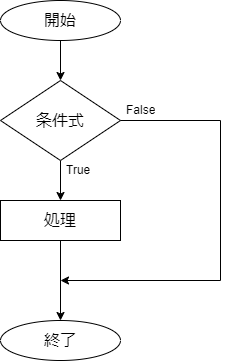
条件式がTrueのときに処理1を実行し、Falseのときに処理2を実行するときは以下のようになります。
処理1・処理2がともに1つのときはIF文で書き換えることができます。
IFB 条件式 THEN
処理1
ELSE
処理2
ENDIF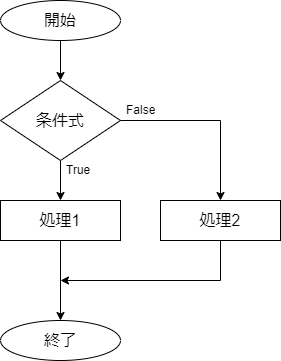
条件式1がTrueのときに処理1を実行します。条件式1がFalseで条件式2がTrueのときは処理2を実行します。条件式2がFalseのときは何も実行しません。
ELSEIF節は条件の数に応じて必要な数だけ記述することができます。
IFB 条件式1 THEN
処理1
ELSEIF 条件式2 THEN
処理2
ENDIF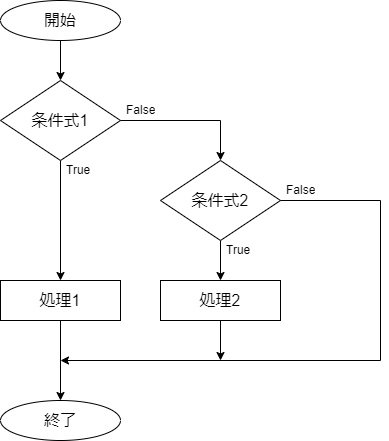
条件式1がTrueのときに処理1を実行します。条件式1がFalseで条件式2がTrueのときは処理2を実行します。条件式2がFalseのときは処理3実行します。
ELSEIF節は条件の数に応じて必要な数だけ記述することができます。
IFB 条件式1 THEN
処理1
ELSEIF 条件式2 THEN
処理2
ELSE
処理3
ENDIF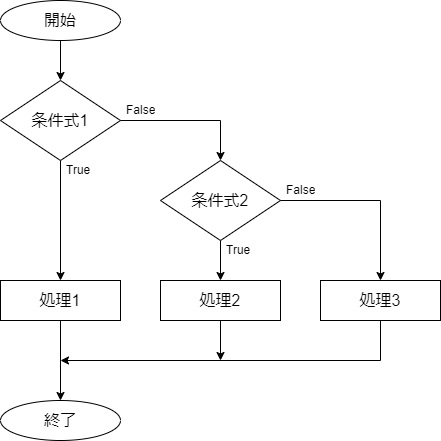
IFB文で使える演算子
比較演算子
比較演算子とは2つの式や値を比較するための演算子で、2つの値が等しい・等しくない、大きい・小さいといった比較ができるようになります。
比較演算子を使うことで、○○と一致したときや○○ではないときといった条件式を書くことができます。
UWSCで使える比較演算子は以下のとおりで、a,bはともに数値が代入されているものとします。
| 演算子 | 記述例 | 意味 |
|---|---|---|
| < | a < b | aがbより小さければ真 |
| <= | a <= b | aがb以下ならば真 |
| > | a > b | aがbより大きければ真 |
| >= | a >= b | aがb以上ならば真 |
| = | a = b | aとbが等しければ真 |
| <> | <> b | aとbが等しくなければ真 |
論理演算子
論理演算子とは、論理演算をするための演算子のことで、論理演算子を使うことで○○かつ○○、○○または○○といった比較演算子だけではできない複数の条件式を比較するといった書き方ができるようになります。
以下の例ではa,bともに論理値(TrueまたはFalse)が代入されているものとします。数値の場合は論理演算ではなくビット演算になるので注意が必要です。
| 演算子 | 記述例 | 意味 |
|---|---|---|
| AND | a AND b | aとbがともに真の場合に真 |
| OR | a OR b | aかbの少なくとも1つが真の場合に真 |
| XOR | a XOR b | aかbのいずれか一方が真の場合に真 |
| ! | !x | xが偽の場合に真 |
IFB文の書き方
以下は分岐させる条件が3つのときの処理の流れを表したものです。
IFB 条件式1 THEN
処理1
ELSEIF 条件式2 THEN
処理2
ELSEIF 条件式3 THEN
処理3
ELSE
処理4
ENDIFIFB文の処理の流れとしては、まず条件式1が成り立つ場合は処理1を実行。条件式1が成り立たず条件式2が成り立つ場合は処理2を実行。条件式2が成り立たず条件式3が成り立つ場合は処理3を実行。どの条件式にも一致しなかった場合はELSE節の処理が実行されます。条件式・処理は必要な数だけ記述することができ、ELSE節は必要がなければ省略することも可能です。
またどこかで条件式が一致した場合、それ以降の条件式の判定は行われません。最初に一致した箇所の処理が終わったらENDIFの直後まで処理が飛びます。
これをまとめると以下のようになります。
IFB 条件式1 THEN
条件式1が真のときの処理
ELSEIF 条件式2 THEN
条件式1が偽で条件式2が真のときの処理
ELSEIF 条件式3 THEN
条件式2が偽で条件式3が真のときの処理
ELSE
いずれの条件式も満たさなかったときの処理
ENDIF以下はscoreの値によって処理を分岐させるプログラムです。scoreの値が90以上ならAと出力します。score >= 90が成り立たなかったら次のELSEIFの条件式が成り立つか調べ80以上ならB、score >= 80が成り立たなかったら次のELSEIFの条件式が成り立つか調べ70以上ならCという風に上から順番に条件式が成り立つかどうかを調べていきます。条件式が成り立ち処理が実行された時点でENDIF直後まで処理が飛び、残りの条件式が成り立つがどうかの判定は行いません。
このプログラムの場合、5行目の条件式(score >= 80)が一致するのでBと出力されます。
DIM score = 85
IF score >= 90 THEN
PRINT "A"
ELSEIF score >= 80 THEN
PRINT "B"
ELSEIF score >= 70 THEN
PRINT "C"
ELSEIF score >= 60 THEN
PRINT "D"
ELSE
PRINT "E"
ENDIF- 結果
B
このプログラムをELSEIFを使わずに書くと以下のようになります。
DIM score = 85
IFB score >= 90 THEN
PRINT "A"
ELSE
IFB score >= 80 THEN
PRINT "B"
ELSE
IFB score >= 70 THEN
PRINT "C"
ELSE
IFB score >= 60 THEN
PRINT "D"
ELSE
PRINT "E"
ENDIF
ENDIF
ENDIF
ENDIFELSEIF文はこれまでに書かれたすべての条件式が成り立たなかったときに実行される条件式なので、以下のようにこれまでに成り立たなかった条件式を改めて書く必要はありません。
5行目のscore >= 80 AND score < 90という条件式は3行目のscore >= 90が成り立たなかったときに実行される条件式なので、5行目に来る時点で90未満なのは確定しています。そのためAND score < 90は書く必要はありません。7行目、9行目のAND以降も同様の理由で必要ありません。
DIM score = 85
IF score >= 90 THEN
PRINT "A"
ELSEIF score >= 80 AND score < 90 THEN
PRINT "B"
ELSEIF score >= 70 AND score < 80 THEN
PRINT "C"
ELSEIF score >= 60 AND score < 70 THEN
PRINT "D"
ELSE
PRINT "E"
ENDIFプログラム実行例
コトバンクで指定した熟語の読みを調べる
4行目のwordに指定した単語の読み方をコトバンクで調べます。
コトバンクに掲載のない単語は取得できません。
DIM WebDriver = CREATEOLEOBJ("Selenium.WebDriver")
WebDriver.Start("chrome")
DIM word = "東京"
WebDriver.Get("https://kotobank.jp/word/" + word)
COM_ERR_IGN
DIM WebElement = WebDriver.FindElementByXPath("//div[@id='mainTitle']//span")
COM_ERR_RET
IFB WebElement <> ERR_VALUE THEN
PRINT REPLACE(WebElement.text, "(読み)", "")
ELSE
PRINT "読みを取得できませんでした。"
ENDIF
WebDriver.Close
//////////////////////////////////////////////////
// 【引数】
// interval : 加算する時間間隔を表す文字列式(yyyy:年、m:月、d:日、ww:週、h:時、n:分、s:秒)
// num : dateに加算する値。未来は正、過去は負で指定
// date : 時間間隔を加算する日付
// 【戻り値】
// 日時(date)に、指定した単位(interval)の時間(num)を加算して返します
//////////////////////////////////////////////////
FUNCTION dateAdd(interval, num, date)
DIM year, month, day, d
GETTIME(0, date)
DIM time = G_TIME_HH2 + ":" + G_TIME_NN2 + ":" + G_TIME_SS2
SELECT interval
CASE "yyyy"
d = (G_TIME_YY + num) + "/" + G_TIME_MM2 + "/" + G_TIME_DD2
IF time <> "00:00:00" THEN d = d + " " + time
CASE "m"
IFB num > 0 THEN
year = G_TIME_YY + INT((G_TIME_MM + num) / 12)
month = REPLACE(FORMAT(((G_TIME_MM + num) MOD 12), 2), " ", "0")
ELSE
year = G_TIME_YY + CEIL((G_TIME_MM + num) / 12 - 1)
month = REPLACE(FORMAT(G_TIME_MM - (ABS(num) MOD 12), 2), " ", "0")
ENDIF
IF month = "00" THEN month = 12
day = G_TIME_DD2
d = "" + year + month + day
IFB !isDate(d) THEN
d = year + "/" + month + "/" + "01"
d = getEndOfMonth(d)
ELSE
d = year + "/" + month + "/" + day
ENDIF
IF time <> "00:00:00" THEN d = d + " " + time
CASE "d"
t = GETTIME(num, date)
d = G_TIME_YY4 + "/" + G_TIME_MM2 + "/" + G_TIME_DD2 + IIF(t MOD 86400, " " + G_TIME_HH2 + ":" + G_TIME_NN2 + ":" + G_TIME_SS2, "")
CASE "ww"
t = GETTIME(num * 7, date)
d = G_TIME_YY4 + "/" + G_TIME_MM2 + "/" + G_TIME_DD2 + IIF(t MOD 86400, " " + G_TIME_HH2 + ":" + G_TIME_NN2 + ":" + G_TIME_SS2, "")
CASE "h"
t = GETTIME(num / 24, date)
d = G_TIME_YY4 + "/" + G_TIME_MM2 + "/" + G_TIME_DD2 + IIF(t MOD 86400, " " + G_TIME_HH2 + ":" + G_TIME_NN2 + ":" + G_TIME_SS2, "")
CASE "n"
t = GETTIME(num / 1440, date)
d = G_TIME_YY4 + "/" + G_TIME_MM2 + "/" + G_TIME_DD2 + IIF(t MOD 86400, " " + G_TIME_HH2 + ":" + G_TIME_NN2 + ":" + G_TIME_SS2, "")
CASE "s"
t = GETTIME(num / 86400, date)
d = G_TIME_YY4 + "/" + G_TIME_MM2 + "/" + G_TIME_DD2 + IIF(t MOD 86400, " " + G_TIME_HH2 + ":" + G_TIME_NN2 + ":" + G_TIME_SS2, "")
SELEND
RESULT = d
FEND
//////////////////////////////////////////////////
// 【引数】
// interval : 時間単位(yyyy︰年、q:四半期、m︰月、d︰日、w:週日、ww:週、h:時、n:分、s:秒)
// date1 : 日時1
// date2 : 日時2
// 【戻り値】
// date2からdate1を引いた時間間隔を求めます。
//////////////////////////////////////////////////
FUNCTION dateDiff(interval, date1, date2)
DIM y1, y2, m1, m2, d1, d2, d
SELECT interval
CASE "yyyy"
GETTIME(0, date1)
y1 = G_TIME_YY
GETTIME(0, date2)
y2 = G_TIME_YY
d = y2 - y1
CASE "q"
GETTIME(0, date1)
y1 = G_TIME_YY
m1 = G_TIME_MM
GETTIME(0, date2)
y2 = G_TIME_YY
m2 = G_TIME_MM
d = y2 * 4 + CEIL(m2/3) - (y1 * 4 + CEIL(m1/3))
CASE "m"
GETTIME(0, date1)
y1 = G_TIME_YY
m1 = G_TIME_MM
GETTIME(0, date2)
y2 = G_TIME_YY
m2 = G_TIME_MM
d = (y2 - y1) * 12 + m2 - m1
CASE "d"
d1 = GETTIME(0, date1)
d2 = GETTIME(0, date2)
d = (d2 - d1) / 86400
CASE "w"
d = INT(dateDiff("d", date1, date2) / 7)
CASE "ww"
date1 = dateAdd("d", -1 * getWeekday(date1), date1)
d = INT(dateDiff("d", date1, date2) / 7)
CASE "h"
d = dateDiff("d", date1, date2) * 24
CASE "n"
d = dateDiff("d", date1, date2) * 1440
CASE "s"
d = dateDiff("d", date1, date2) * 86400
SELEND
RESULT = d
FEND
//////////////////////////////////////////////////
// 【引数】
// array : 最大公約数を求める数値を格納した配列
// 【戻り値】
// 最大公約数
//////////////////////////////////////////////////
FUNCTION GCD(array[])
DIM c = LENGTH(array)
DIM rem = array[c-1] MOD array[c-2]
IFB rem = 0 THEN
IFB LENGTH(array) = 2 THEN
RESULT = array[c-2]
EXIT
ENDIF
RESIZE(array, c-2)
RESULT = GCD(array)
EXIT
ENDIF
array[c-1] = array[c-2]
array[c-2] = rem
RESULT = GCD(array)
FEND
//////////////////////////////////////////////////
// 【引数】
// date : 日付(”YYYYMMDD” or “YYYY/MM/DD” or “YYYY-MM-DD” or “YYYYMMDDHHNNSS” or “YYYY/MM/DD HH:NN:SS”)
// m : 第一引数の指定日からプラスマイナスm月とする
// 【戻り値】
// dateからm月後の月末の日付
//////////////////////////////////////////////////
FUNCTION getEndOfMonth(date, m = 0)
date = dateAdd("m", m + 1, date)
GETTIME(0, date)
GETTIME(-G_TIME_DD, date)
RESULT = G_TIME_YY4 + "/" + G_TIME_MM2 + "/" + G_TIME_DD2
FEND
//////////////////////////////////////////////////
// 【引数】
// date : 日付文字列(”YYYYMMDD” or “YYYY/MM/DD” or “YYYY-MM-DD” or “YYYYMMDDHHNNSS” or “YYYY/MM/DD HH:NN:SS”)もしくはシリアル値
// type : 取得する曜日番号の種類を示す0〜3または11〜17の値。1と17は日曜日を1、2と11は月曜日を1とカウントします。11以降はExcel2010で追加された値で、互換性を保つために重複した値があります。
// 【戻り値】
// typeで指定した種類によって以下の値を返します。 : (0 : 0(日曜)〜6(土曜)、1 : 1(日曜)~7(土曜)、2 : 1(月曜)~7(日曜)、3 : 0(月曜)〜6(日曜)、11 : 1(月曜)~7(日曜)、12 : 1(火曜)~7(月曜)、13 : 1(水曜)~7(火曜)、14 : 1(木曜)~7(水曜)、15 : 1(金曜)~7(木曜)、16 : 1(土曜)~7(金曜)、17 : 1(日曜)~7(土曜))
//////////////////////////////////////////////////
FUNCTION getWeekday(date, type = 1)
IF VARTYPE(date) <> 258 THEN date = text(date, "yyyy/mm/dd")
GETTIME(0, date)
DIM w = G_TIME_WW
SELECT TRUE
CASE type = 0
RESULT = w
CASE type = 1
RESULT = w + 1
CASE type = 2
RESULT = IIF(w=0, 7, w)
CASE type = 3
RESULT = (w+6) MOD 7
CASE type >= 11
RESULT = ((getWeekday(date, 2) + 17 - type) MOD 7) + 1
SELEND
FEND
//////////////////////////////////////////////////
// 【引数】
// serial : シリアル値もしくは時刻文字列
// 【戻り値】
// 時刻から時間を表す0〜23の範囲の値
//////////////////////////////////////////////////
FUNCTION Hour(serial)
IF VARTYPE(serial) = 258 THEN serial = timeValue(serial)
RESULT = INT(serial * 24) MOD 24
FEND
//////////////////////////////////////////////////
// 【引数】
// expr : 評価する式
// truepart : 評価した式がTrueのときに返す値
// falsepart : 評価した式がFalseのときに返す値
// 【戻り値】
// truepart : 評価した式がTrueのとき、falsepart : 評価した式がFalseのとき
//////////////////////////////////////////////////
FUNCTION IIF(expr, truepart, falsepart)
IFB EVAL(expr) THEN
RESULT = truepart
ELSE
RESULT = falsepart
ENDIF
FEND
//////////////////////////////////////////////////
// 【引数】
// date : 存在するかを調べる日付文字列。YYYYMMDD or YYYY/MM/DD or YYYY-MM-DDのいずれかの形式。
// 【戻り値】
// TRUE : 日付として認識できる、FALSE : 日付として認識できない
//////////////////////////////////////////////////
FUNCTION isDate(date)
TRY
GETTIME(0, date)
RESULT = TRUE
EXCEPT
RESULT = FALSE
ENDTRY
FEND
//////////////////////////////////////////////////
// 【引数】
// str : 正規表現による検索の対象となる文字列
// Pattern : 正規表現で使用するパターンを設定
// IgnoreCase : 大文字・小文字を区別しない場合はTrue、区別する場合はFalse
// Global : 文字列全体を検索する場合はTrue、しない場合はFalse
// 【戻り値】
// 正規表現で検索した結果をMatchesコレクションとして返します。
//////////////////////////////////////////////////
FUNCTION reExecute(str, Pattern, IgnoreCase = TRUE, Global = TRUE)
DIM re = CREATEOLEOBJ("VBScript.RegExp")
re.Pattern = Pattern
re.IgnoreCase = IgnoreCase
re.Global = Global
RESULT = re.Execute(str)
FEND
//////////////////////////////////////////////////
// 【引数】
// str : 正規表現による検索の対象となる文字列
// Pattern : 正規表現で使用するパターンを設定
// IgnoreCase : 大文字・小文字を区別しない場合はTrue、区別する場合はFalse
// Global : 文字列全体を検索する場合はTrue、しない場合はFalse
// 【戻り値】
// 正規表現にマッチするかどうかを示すブール値
//////////////////////////////////////////////////
FUNCTION reTest(str, Pattern, IgnoreCase = TRUE, Global = TRUE)
DIM re = CREATEOLEOBJ("VBScript.RegExp")
re.Pattern = Pattern
re.IgnoreCase = IgnoreCase
re.Global = Global
RESULT = re.Test(str)
FEND
//////////////////////////////////////////////////
// 【引数】
// inputs : 繰り返す文字列
// multiplier : inputsを繰り返す回数
// 【戻り値】
// inputsをmultiplier回を繰り返した文字列を返します
//////////////////////////////////////////////////
FUNCTION strRepeat(inputs, multiplier)
DIM res = ""
FOR n = 1 TO multiplier
res = res + inputs
NEXT
RESULT = res
FEND
//////////////////////////////////////////////////
// 【引数】
// serial : シリアル値
// format : フォーマット
// 【戻り値】
// 数値を表示書式に基づいて変換した文字列
//////////////////////////////////////////////////
FUNCTION text(serial, format, hour12 = FALSE)
HASHTBL startDate
startDate["明治"] = "1868/01/25"
startDate["大正"] = "1912/07/30"
startDate["昭和"] = "1926/12/25"
startDate["平成"] = "1989/01/08"
startDate["令和"] = "2019/05/01"
DIM baseDate = "1899/12/30"
serial = VAL(serial)
SELECT TRUE
CASE reTest(format, "\[h+\]")
Matches = reExecute(format, "\[(h+)\]")
DIM hour = iif(hour12, Hour(serial) MOD 12, Hour(serial))
RESULT = text(hour, strRepeat("0", LENGTH(Matches.Item(0).SubMatches(0))))
CASE reTest(format, "^h+$")
Matches = reExecute(format, "^(h+)$")
hour = iif(hour12, Hour(serial) MOD 12, Hour(serial))
RESULT = text(hour MOD 24, strRepeat("0", LENGTH(Matches.Item(0).SubMatches(0))))
CASE reTest(format, "\[m+\]")
Matches = reExecute(format, "\[(m+)\]")
RESULT = text(serial * 1440, strRepeat("0", LENGTH(Matches.Item(0).SubMatches(0))))
CASE format = "m"
GETTIME(serial, baseDate)
RESULT = text(G_TIME_MM, "0")
CASE format = "mm"
GETTIME(serial, baseDate)
RESULT = G_TIME_MM2
CASE format = "n"
GETTIME(serial, baseDate)
RESULT = G_TIME_NN
CASE format = "nn"
GETTIME(serial, baseDate)
RESULT = G_TIME_NN2
CASE format = "s"
GETTIME(serial, baseDate)
RESULT = text(G_TIME_SS, "0")
CASE format = "ss"
GETTIME(serial, baseDate)
RESULT = G_TIME_SS2
CASE format = "yyyy"
GETTIME(serial, baseDate)
RESULT = G_TIME_YY4
CASE format = "yy"
GETTIME(serial, baseDate)
RESULT = COPY(G_TIME_YY4, 3, 2)
CASE format = "e"
SELECT TRUE
CASE dateDiff("d", startDate["令和"], text(serial, "yyyy/mm/dd")) >= 0
RESULT = text(serial, "yyyy") - 2018
CASE dateDiff("d", startDate["平成"], text(serial, "yyyy/mm/dd")) >= 0
RESULT = text(serial, "yyyy") - 1988
CASE dateDiff("d", startDate["昭和"], text(serial, "yyyy/mm/dd")) >= 0
RESULT = text(serial, "yyyy") - 1925
CASE dateDiff("d", startDate["大正"], text(serial, "yyyy/mm/dd")) >= 0
RESULT = text(serial, "yyyy") - 1911
CASE dateDiff("d", startDate["明治"], text(serial, "yyyy/mm/dd")) >= 0
RESULT = text(serial, "yyyy") - 1867
SELEND
CASE format = "ee"
SELECT TRUE
CASE dateDiff("d", startDate["令和"], text(serial, "yyyy/mm/dd")) >= 0
RESULT = text(text(serial, "yyyy") - 2018, "00")
CASE dateDiff("d", startDate["平成"], text(serial, "yyyy/mm/dd")) >= 0
RESULT = text(text(serial, "yyyy") - 1988, "00")
CASE dateDiff("d", startDate["昭和"], text(serial, "yyyy/mm/dd")) >= 0
RESULT = text(text(serial, "yyyy") - 1925, "00")
CASE dateDiff("d", startDate["大正"], text(serial, "yyyy/mm/dd")) >= 0
RESULT = text(text(serial, "yyyy") - 1911, "00")
CASE dateDiff("d", startDate["明治"], text(serial, "yyyy/mm/dd")) >= 0
RESULT = text(text(serial, "yyyy") - 1867, "00")
SELEND
CASE format = "g"
SELECT TRUE
CASE dateDiff("d", startDate["令和"], text(serial, "yyyy/mm/dd")) >= 0; RESULT = "R"
CASE dateDiff("d", startDate["平成"], text(serial, "yyyy/mm/dd")) >= 0; RESULT = "H"
CASE dateDiff("d", startDate["昭和"], text(serial, "yyyy/mm/dd")) >= 0; RESULT = "S"
CASE dateDiff("d", startDate["大正"], text(serial, "yyyy/mm/dd")) >= 0; RESULT = "T"
CASE dateDiff("d", startDate["明治"], text(serial, "yyyy/mm/dd")) >= 0; RESULT = "M"
SELEND
CASE format = "gg"
RESULT = COPY(text(serial, "ggg"), 1, 1)
CASE format = "ggg"
SELECT TRUE
CASE dateDiff("d", startDate["令和"], text(serial, "yyyy/mm/dd")) >= 0; RESULT = "令和"
CASE dateDiff("d", startDate["平成"], text(serial, "yyyy/mm/dd")) >= 0; RESULT = "平成"
CASE dateDiff("d", startDate["昭和"], text(serial, "yyyy/mm/dd")) >= 0; RESULT = "昭和"
CASE dateDiff("d", startDate["大正"], text(serial, "yyyy/mm/dd")) >= 0; RESULT = "大正"
CASE dateDiff("d", startDate["明治"], text(serial, "yyyy/mm/dd")) >= 0; RESULT = "明治"
SELEND
CASE format = "mmmmm"
RESULT = COPY(text(serial, "mmmm"), 1, 1)
CASE format = "mmmm"
DIM month[] = "January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December"
RESULT = month[text(serial, "m") - 1]
CASE format = "mmm"
RESULT = COPY(text(serial, "mmmm"), 1, 3)
CASE format = "dd"
GETTIME(serial, baseDate)
RESULT = text(G_TIME_DD2, "00")
CASE format = "d"
GETTIME(serial, baseDate)
RESULT = text(G_TIME_DD, "0")
CASE reTest(format, "^[ad]{3,4}$")
Matches = reExecute(format, "([ad]{3,4})")
GETTIME(serial, baseDate)
DIM aaa[] = "日", "月", "火", "水", "木", "金", "土"
DIM aaaa[] = "日曜日", "月曜日", "火曜日", "水曜日", "木曜日", "金曜日", "土曜日"
DIM ddd[] = "Sun", "Mon", "Tue", "Wed", "Thu", "Fri", "Sat"
DIM dddd[] = "Sunday", "Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday";
RESULT = EVAL(Matches.Item(0).SubMatches(0) + "[" + getWeekday(G_TIME_WW, 1) + "]")
CASE reTest(format, "(0+\.?0+)?%")
Matches = reExecute(format, "(0+\.?0+)?%")
RESULT = text(serial * 100, Matches.Item(0).SubMatches(0)) + "%"
CASE reTest(format, "^\[DBNum\d{1,4}\](.*?)$")
Matches = reExecute(format, "^\[DBNum(\d{1,4})\](.*?)$")
DIM value = VAL(Matches.Item(0).SubMatches(0))
DIM sss = text(serial, Matches.Item(0).SubMatches(1))
Matches = reExecute(sss, "(\D+)?(\d+)(\D+)?")
DIM res = ""
FOR m = 0 TO Matches.Count - 1
serial = Matches.Item(m).SubMatches(1)
SELECT value
CASE 1, 2
DIM n[][9] = "〇", "一", "二", "三", "四", "五", "六", "七", "八", "九", + _
"", "壱", "弐", "参", "四", "伍", "六", "七", "八", "九"
DIM a[][3] = "", "十", "百", "千", + _
"", "拾", "百", "阡"
DIM b[][3] = "", "万", "億", "兆", + _
"", "萬", "億", "兆"
DIM r = ""
DIM j = 0
type = value - 1
REPEAT
DIM str = ""
DIM n4 = serial MOD 10000
FOR i = LENGTH(n4) TO 1 STEP -1
s = COPY(n4, i, 1)
IFB s = 1 AND a[type][LENGTH(n4)-i] <> "" THEN
str = IIF(s, a[type][LENGTH(n4)-i], "") + str
ELSE
str = n[type][s] + IIF(s, a[type][LENGTH(n4)-i], "") + str
ENDIF
NEXT
IF str <> "" THEN r = str + b[type][j] + r
j = j + 1
serial = INT(serial / 10000)
UNTIL serial = 0
res = res + Matches.Item(m).SubMatches(0) + r + Matches.Item(m).SubMatches(2)
CASE 3
res = res + Matches.Item(m).SubMatches(0) + STRCONV(serial, SC_FULLWIDTH) + Matches.Item(m).SubMatches(2)
CASE 4
res = res + Matches.Item(m).SubMatches(0) + STRCONV(serial, SC_HALFWIDTH) + Matches.Item(m).SubMatches(2)
SELEND
NEXT
RESULT = res
CASE reTest(format, "^(.*?)(AM\/PM|am\/pm|A\/P|a\/p)(.*?)$")
Matches = reExecute(format, "^(.*?)(AM\/PM|am\/pm|A\/P|a\/p)(.*?)$")
DIM array = SPLIT(Matches.Item(0).SubMatches(1), "/")
ampm = array[IIF(serial - INT(serial) >= 0.5, 1, 0)]
hour12 = TRUE
res = ""
WITH Matches.Item(0)
res = text(serial, .SubMatches(0), hour12) + ampm + text(serial, .SubMatches(2), hour12)
ENDWITH
RESULT = res
CASE reTest(format, "([^ymdagehns]{0,})?(([ymdagehns])\3{0,})([^ymdagehns]+)?")
Matches = reExecute(format, "([^ymdagehns]{0,})?(([ymdagehns])\3{0,})([^ymdagehns]+)?")
FOR n = 0 TO Matches.Count - 1
IF n = 0 THEN res = Matches.Item(n).SubMatches(0)
NEXT
FOR n = 0 TO Matches.Count - 1
WITH Matches.Item(n)
res = res + text(serial, .SubMatches(1), hour12) + .SubMatches(3)
ENDWITH
NEXT
RESULT = res
CASE format = "0/0"
DIM separator = POS(".", serial)
DIM g = 0
IFB separator <> 0 THEN
DIM keta = LENGTH(serial)
DIM shift = POWER(10, keta - separator)
IFB shift >= POWER(10, 15) THEN
DIM position = 0
FOR i = 0 TO 14
IFB serial * POWER(10, i) - serial >= 1 THEN
position = i
BREAK
ENDIF
NEXT
tmp = serial * POWER(10, position)
FOR i = 1 TO 15
r = (tmp * POWER(10, i)) / serial - (tmp / serial)
a1 = tmp * POWER(10, i) - tmp
IF a1 = INT(a1) THEN BREAK
NEXT
DIM frac[] = a1, r
g = GCD(frac)
RESULT = (a1/g) + "/" + (r/g)
ELSE
DIM molecule = serial * shift // 分子
DIM denominator = shift // 分母
DIM nums[] = molecule, denominator
g = GCD(nums)
molecule = molecule / g
denominator = denominator / g
RESULT = molecule + "/" + denominator
ENDIF
ELSE
RESULT = serial + "/1"
ENDIF
CASE reTest(format, "(0+)\.?(0+)?") AND UBound(SPLIT(format, ".")) <= 1
Matches = reExecute(format, "(0+)\.?(0+)?")
len1 = LENGTH(Matches.Item(0).SubMatches(0))
len2 = LENGTH(Matches.Item(0).SubMatches(1))
DIM arr[] = LENGTH(INT(serial)), len1
IFB POS(".", format) THEN
RESULT = REPLACE(FORMAT(serial, CALCARRAY(arr, CALC_MAX) + len2 + 1, len2), " ", "0")
ELSE
RESULT = REPLACE(FORMAT(serial, CALCARRAY(arr, CALC_MAX)), " ", "0")
ENDIF
SELEND
FEND
//////////////////////////////////////////////////
// 【引数】
// str : 時刻文字列。hh:nn:ss AM/PM、hh:nn AM/PM、hh AM/PM、hh:nn:ss、hh:nn、hh時nn分ss秒、hh時nn分のいずれかの形式を指定。
// 【戻り値】
// シリアル値 (例)0…00:00:00、0.5…12:00:00、0.999988425925926…23:59:59
//////////////////////////////////////////////////
FUNCTION timeValue(str)
DIM serial = 0
DIM Matches
DIM pattern = "(\d+)"
DIM hh = "(0?[0-9]|1[0-2])"
DIM ampm = "([AP]M|[ap]m)"
SELECT TRUE
CASE reTest(str, "\b" + hh + ":" + pattern + ":" + pattern + " " + ampm + "\b")
Matches = reExecute(str, "\b" + hh + ":" + pattern + ":" + pattern + " " + ampm + "\b")
WITH Matches.Item(0)
serial = timeValue(.SubMatches(0) + " " + .SubMatches(3)) + VAL(.SubMatches(1)) / 1440 + VAL(.SubMatches(2)) / 86400
ENDWITH
CASE reTest(str, "\b" + hh + ":" + pattern + " " + ampm + "\b")
Matches = reExecute(str, "\b" + hh + ":" + pattern + " " + ampm + "\b")
WITH Matches.Item(0)
serial = timeValue(.SubMatches(0) + " " + .SubMatches(2)) + VAL(.SubMatches(1)) / 1440
ENDWITH
CASE reTest(str, "\b" + hh + " " + ampm + "\b")
Matches = reExecute(str, "\b" + hh + " " + ampm + "\b")
WITH Matches.Item(0)
serial = VAL(.SubMatches(0) MOD 12) + IIF(reTest(.SubMatches(1), "AM|am"), 0, 12)
serial = serial / 24
ENDWITH
CASE reTest(str, "\b" + pattern + ":" + pattern + ":" + pattern + "\b")
Matches = reExecute(str, "\b" + pattern + ":" + pattern + ":" + pattern + "\b")
WITH Matches.Item(0)
serial = VAL(.SubMatches(0)) / 24 + VAL(.SubMatches(1)) / 1440 + VAL(.SubMatches(2)) / 86400
ENDWITH
CASE reTest(str, "\b" + pattern + ":" + pattern + "\b")
Matches = reExecute(str, "\b" + pattern + ":" + pattern + "\b")
WITH Matches.Item(0)
serial = VAL(.SubMatches(0)) / 24 + VAL(.SubMatches(1)) / 1440
ENDWITH
CASE reTest(str, "\b" + pattern + "時" + pattern + "分" + pattern + "秒")
Matches = reExecute(str, "\b" + pattern + "時" + pattern + "分" + pattern + "秒")
WITH Matches.Item(0)
serial = VAL(.SubMatches(0)) / 24 + VAL(.SubMatches(1)) / 1440 + VAL(.SubMatches(2)) / 86400
ENDWITH
CASE reTest(str, "\b" + pattern + "時" + pattern + "分")
Matches = reExecute(str, "\b" + pattern + "時" + pattern + "分")
WITH Matches.Item(0)
serial = VAL(.SubMatches(0)) / 24 + VAL(.SubMatches(1)) / 1440
ENDWITH
DEFAULT
serial = ERR_VALUE
SELEND
RESULT = serial - INT(serial)
FEND
//////////////////////////////////////////////////
// 【引数】
// arrayname : 上限値を求める配列の名前
// dimension : 返す次元を示す整数
// 【戻り値】
// 配列の上限値
//////////////////////////////////////////////////
FUNCTION UBound(arrayname[], dimension = 1)
RESULT = EVAL("RESIZE(arrayname" + strRepeat("[0]", dimension - 1) + ")")
FENDトウキョウ